自社では Sphinx というドキュメントツールを利用しているのですが、残念ながらこれに付属している検索機能の日本語検索はかなり厳しいです。また残念ながら Sphinx 開発側も検索周りを改善するという予定は直近ではないようです。
そして検索というのはとても難しい技術なため自分のような素人では導入して「普通に期待する動作」をさせるまでの距離はとても遠いです。
ただ、なんとかして日本語全文検索を実現したいという思いはここ10 年くらいずっと思っていました。これは自社の Sphinx テーマを作ってくれている社員ともよく話をしていたのですが、どうしてもリソースをつぎ込めずにいました。
まとめ
- 日本語検索に対応している Meilisearch を採用した
- ドキュメントスクレイパーの実行は GItHub Actions (Self-hosted Runner) を採用した
- 自社 Sphinx テーマの検索バーへ組み込む
ドキュメントの重要性
企業製品にとってドキュメントはとても重要です。自社のようなミドルウェア製品、かつクローズドソースの場合はドキュメントがすべてになります。自社でもドキュメントにはかなり力を入れています。
力を入れているドキュメントで検索がいけてないというのは本当に歯がゆい状態でした。実際顧客から検索が使い物にならないというお問い合わせを頂いたこともありました。
Algolia を検討
検索 SaaS といえば https://www.algolia.com/ です。最初はこれを使おうと思っていたのですが、日本語がどうなのかがいまいちわからなかったというのがあります。また、残念ながら多機能すぎて検証するまでの距離も長いです。
さらにオンラインドキュメント検索ツールは OSS 限定のため商用製品では利用できません。
Meilisearch を検討
いろいろ調べていたら辿り着いたのが Meilisearch (ちなみにメイリサーチと発音するようです、YouTube で中の人の発音を確認するかぎり)です。
Meilisearch はパリのスタートアップ?が開発している Rust で書かれた検索エンジンです。動かすまでが本当に簡単でバイナリダウンロードしてきてすぐに動かせます。
また docs-scraper という HTML ドキュメントを解析して検索インデックスを作成してくれるツールが Python で用意されていました。(もともとこれは Algolia が公開していたモノをベースに作ったようです)
ドキュメントもしっかりと書かれており一通り読み込んで見た限り、どうやら自分がやりたいことが実現しているということがわかりました。
Meilisearch を検証
検索エンジンで一番重要なのが「日本語への対応」です。何でもかんでも日本語に対応しているわけではありません。海外のドキュメントサービスなんて基本日本語に対応していません。
Meilisearch は v0.27.0 にて日本語に対応しています。これを実現しているのは Lindera という kuromoji-rs のフォーク実装です。
実際に docs-scraper で自社製品ドキュメントを読み取ったら問題なく日本語が検索できました。
Meilisearch を採用
Meilisearch はプライベートベータでクラウドサービスを展開しているのですが、残念ながら日本リージョンがないことから見送りました。
また結局 docs-scraper を定期実行する必要があるため、自前で構築する方針をとりました。
構成はシンプルです Cloudflare DNS Proxy + Nginx + Meilisearch だけです。
サーバーは CPU バウンドになることを考えて Linode の専有インスタンス 2C/4G を採用しました。費用は月 $30 です。
実際に複数のドキュメントのインデックスを追加してみたところ特に問題なく処理できていました。
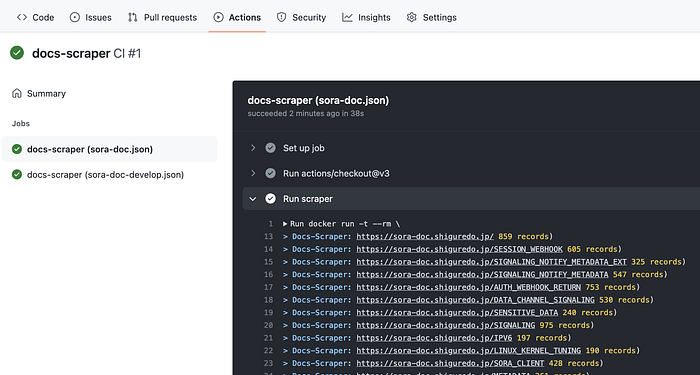
docs-scraper 実行には GitHub Actions (Self-hosted runner) を採用
docs-scraper はドキュメントに対して定期実行する必要があります。ドキュメントが変わったら検索インデックスも変更する必要があります。
頻繁にインデックスを更新したいと考えていたのと、Meilisearch の近くで docs-scraper を実行したいと考えていたので今回は GitHub Actions (Self-hosted runner) を採用しました。
Self-hosted runner は自分の用意したサーバーで GitHub Actions を実行する仕組みです。以前に触ってみてとても簡単に構築することができるのを覚えていたので、今回試してみました。
実際ためしたらより構築が簡単になっていてびっくりしました。
構築して GitHub 側に Self-hosted runner が認識されてしまえば、あとは普通に GitHub Actions の YAML を書くだけです。
on:
push:
paths-ignore:
- '**.md'
branches: [ "main" ]
pull_request:
branches: [ "main" ]workflow_dispatch:schedule:
# JST は 2:00 は UTC の 17:00
# 1-5 で 月曜日から金曜日
- cron: '0 17 * * 1-5'jobs:
docs-scraper:
runs-on: [self-hosted, linux, x64]
strategy:
max-parallel: 1
matrix:
config: [sample1.json, sample2.json]steps:
- uses: actions/checkout@v3
- name: Run scraper
env:
HOST_URL: ${{ secrets.MEILISEARCH_HOST_URL }}
API_KEY: ${{ secrets.MEILISEARCH_API_KEY }}
CONFIG_FILE_PATH: ${{ github.workspace }}/${{ matrix.config }}
run: |
docker run -t --rm \
--network host \
-e MEILISEARCH_HOST_URL=$HOST_URL \
-e MEILISEARCH_API_KEY=$API_KEY \
-v $CONFIG_FILE_PATH:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
docker run して終わりです。あとは好きなだけドキュメントを登録します。これでドキュメントをスクレイピングしてインデックスを張るところまでは用意できました。
ちなみに誰も使って居なさそうな丑三つ時にスクレイピングを実行しています。
動作
実際に動かしてみると期待以上の結果でした。サーバ通信が発生しているとは思えない速度、そして雑に解析を設定したと思えない精度。

Sphinx テーマに docs-searchbar.js を組み込む
Sphinx 用の自社 テーマを持っているため、これの検索部分を Meilisearch が用意している docs-searchbar.js に置き換えてしまえばもう終わりです。
組み込むべき JavaScript はたったこれだけです。
import docsSearchBar from 'docs-searchbar.js'
docsSearchBar({
hostUrl: 'https://meilisearch.example.com/',
apiKey: 'xxx',
indexUid: 'doc',
inputSelector: '#search-bar-input',
})カスタマイズもいろいろ出来るようなので、テーマに合う感じでデザインを変更し、使いやすく組み込みました。
利用するには Sphinx の conf.py にて以下を設定するだけで利用可能です。
html_theme_options = {
'meilisearch': True,
'meilisearch_api_key': 'xxx',
'meilisearch_host_url': 'https://meilisearch.example.com/',
'meilisearch_index_uid': 'doc'
}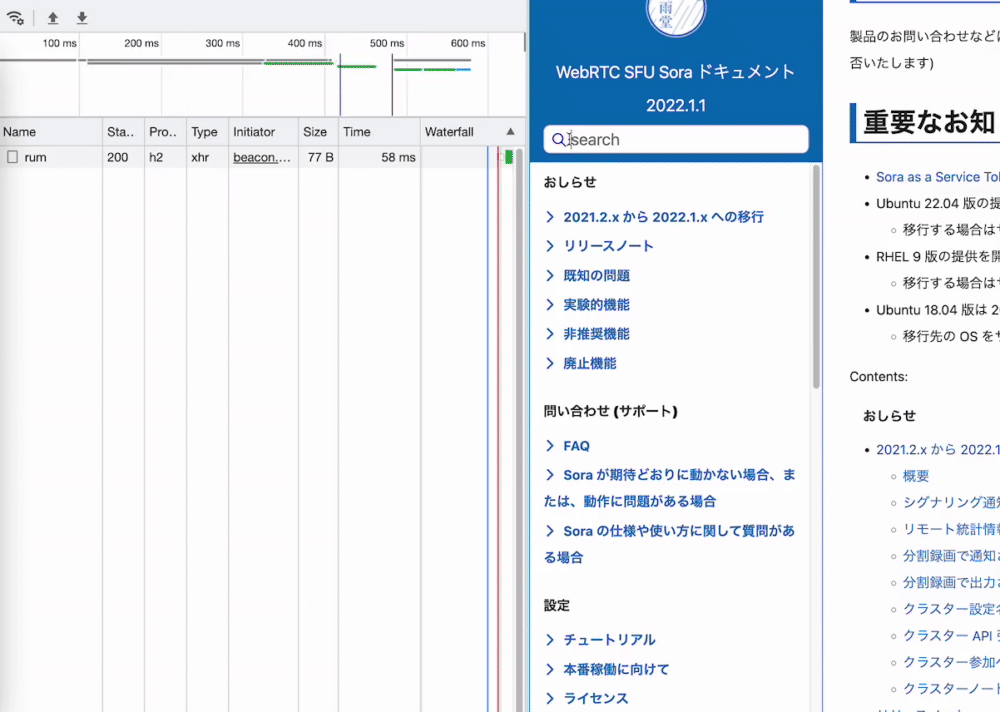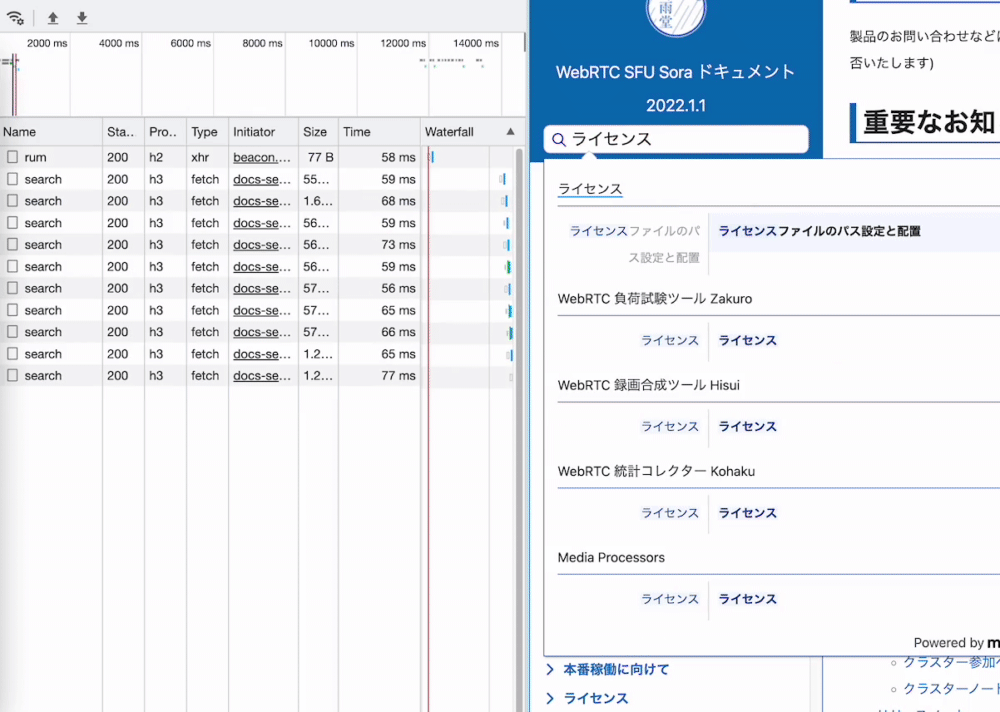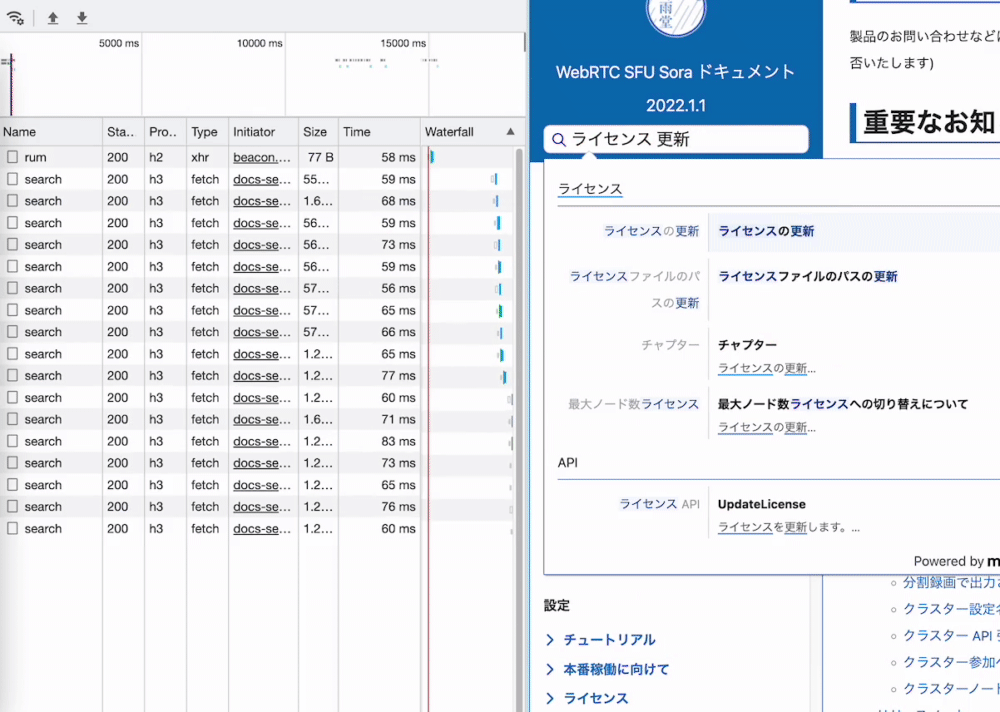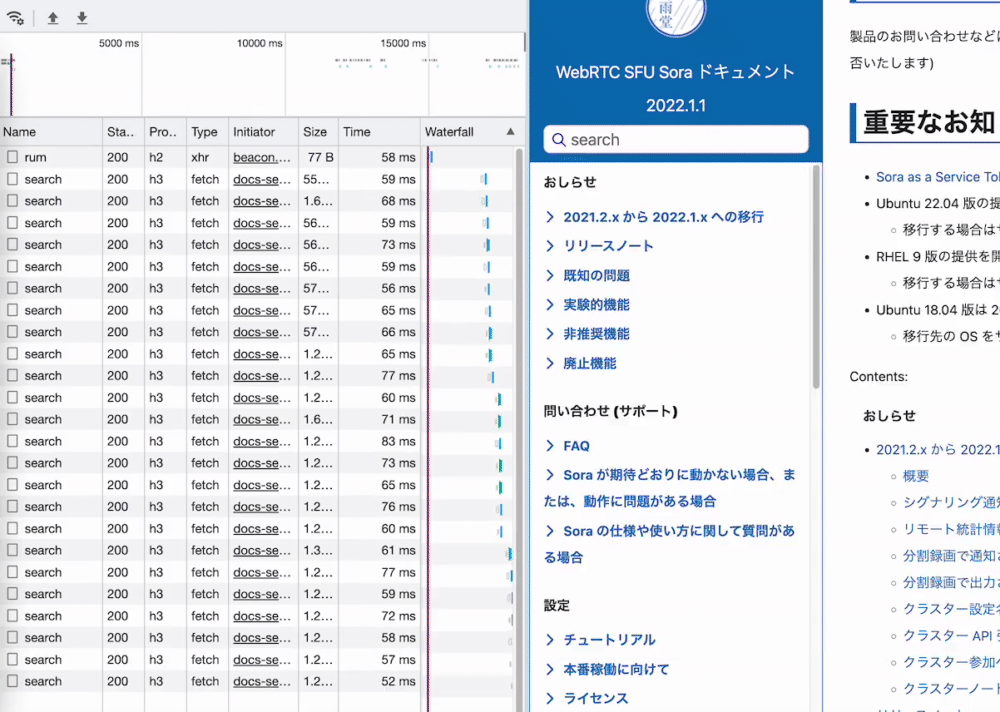
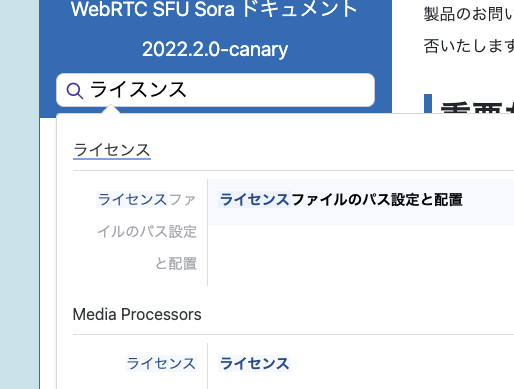
タイポ耐性
雑感
ドキュメントの日本語全文検索はとにかく難しいので手を出してはならぬという考えが強かったのですが、今回の Meilisearch と Sphinx の組み合わせはとても満足できる結果になりそうです。
費用も 月 $ 30 だけですし検索対象のドキュメントは好きなだけ増やせます。Meilisearch の検証、構築で 3 日、Sphinx 組み込みで 2 日程度で実現出来そうなのでコスパも不満なしです。
ねんがんのオンラインドキュメントツールでの日本語検索が実現できて大変満足しています。
